Since the publication of our recent blog post, PowerSync unveiled a new, significantly more cost-effective pricing structure and introduced both a React Native Client SDK and a JavaScript web SDK, enriching their platform’s capabilities and compatibility.
When building our first LMS we were often asked to solve two very interesting problems, namely the lack of electricity availability, due to load shedding, and the absence of a reliable internet connection. The reality in South Africa is that being always online is a privilege.
So we needed to design and build a system that could still be effective even when there’s no electricity or an internet connection. Why? So that the users who face these challenges daily can still have access to the value provided by the system.
Offline -first
When we think of web or mobile applications, we inherently assume they’re online. That’s true most of the time; I’m used to expecting an application not to work when I don’t have an internet connection. However, there’s a shift in this paradigm known as offline-first where the software must work as well offline as it does online.
The primary aim of this approach is to provide a seamless user experience regardless of network connectivity. Popular apps like Google Docs and Evernote use this approach to allow users to create and edit documents or notes while offline and then sync these changes to the cloud when they’re back online.
What does this mean in the context of our LMS? It means a complete shift in design and architecture. You cannot simply build an API and allow the application to call the API if and when data is needed. You need to consider what tech you can and should use to achieve offline-first carefully.
How we achieved this
Let’s look at the client application first followed by the fetching and storing of data.
The client application
This needs to be software that can live on a device offline and not require an active internet connection to render the application to the user. An obvious option is a mobile application, that is, by design, a piece of software installed on a device. This is great if you’re looking to build a mobile-only application.
A web application, on the other hand, is accessed in the browser over the internet. Here we can take advantage of something called a Progressive Web App (PWA). This is a web app that runs in the browser, has the capabilities of a platform-specific app, and can be ‘installed’ on the device. And yes, it can be used offline as well.
A PWA has the advantage of being available on any device that has a browser and therefore has higher reach than a mobile application. We picked out our preferred Javascript framework that can easily deliver a PWA, which in this case happened to be Angular. This marked the first problem as resolved.
Fetching and storing of data
The API layer is usually used to fetch data when it’s needed from the backend. With an offline-first approach, you can’t be sure when the device will go offline. So, if you haven’t fetched the data a certain section of the app requires, you won’t be able to use the app when it goes offline. In short, you need to be able to fetch all required data for the app to function offline and store it locally on the device before the device goes offline.
The app can use local storage as a primary interface for supplying the required data to the views. Any user interactions that result in data being written to the backend can first be stored in local storage and synced to the backend when and if there is a connection.
Offline database solutions
We considered a few options that would help us achieve this:
PowerSync
First in line was a solution called PowerSync. This solution is specifically built to enable an offline-first architecture for real-time reactive apps, and helps solve the varying complexities that come with this problem. At the time of consideration, two blockers were introduced.
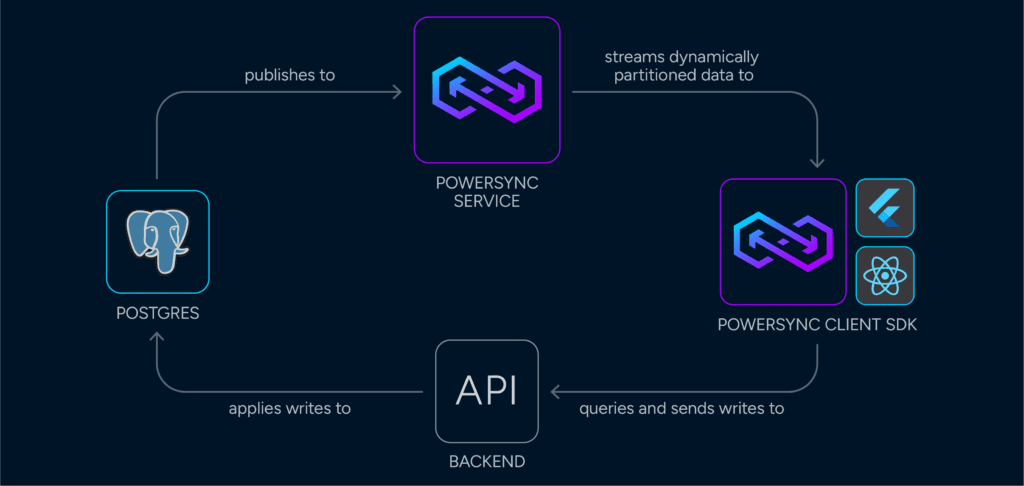
The first was that they only supported PostgreSQL databases on the backend, and a Flutter client SDK for a Flutter front end that can run on devices supporting SqlLite. This would’ve forced our hand into using an expensive provisioned PostgreSQL database on our AWS backend, and the language and framework (Dart and Flutter) on the front end. Big curveball – browsers don’t support SqlLite – so, a PWA solution with PowerSync goes out the window. The second issue is this all came with a hefty price tag. Unfortunately, we had to look for something else.
RxDB
RxDB is an open-source Javascript database library that wraps the native web database, IndexedDB, with some really nifty enhancements. It enables real-time reactive queries, and easy-to-use client-to-server replication functionality – and vice versa. The replication protocol supports integration points using GraphQL, CouchDB, Websockets, P2P, Firestore, NATS, or REST API technologies. After thorough research, this solution came out as the top contender, and ultimately what we went with.
PouchDB – a notable mention
PouchDB is another offline-first browser database solution. It offers the same functionality as PowerSync and RxDB but is only compatible with an Apache CouchDB database on the server. It was fun to learn about but it would’ve forced us into a specific database on the backend which we were trying to avoid.
How we used RxDB
The local database is used as a primary interface for the views to read from and write to. Whether the application is online or offline, this doesn’t change. What does change is the syncing of the data from the server to the client and the client to the server.
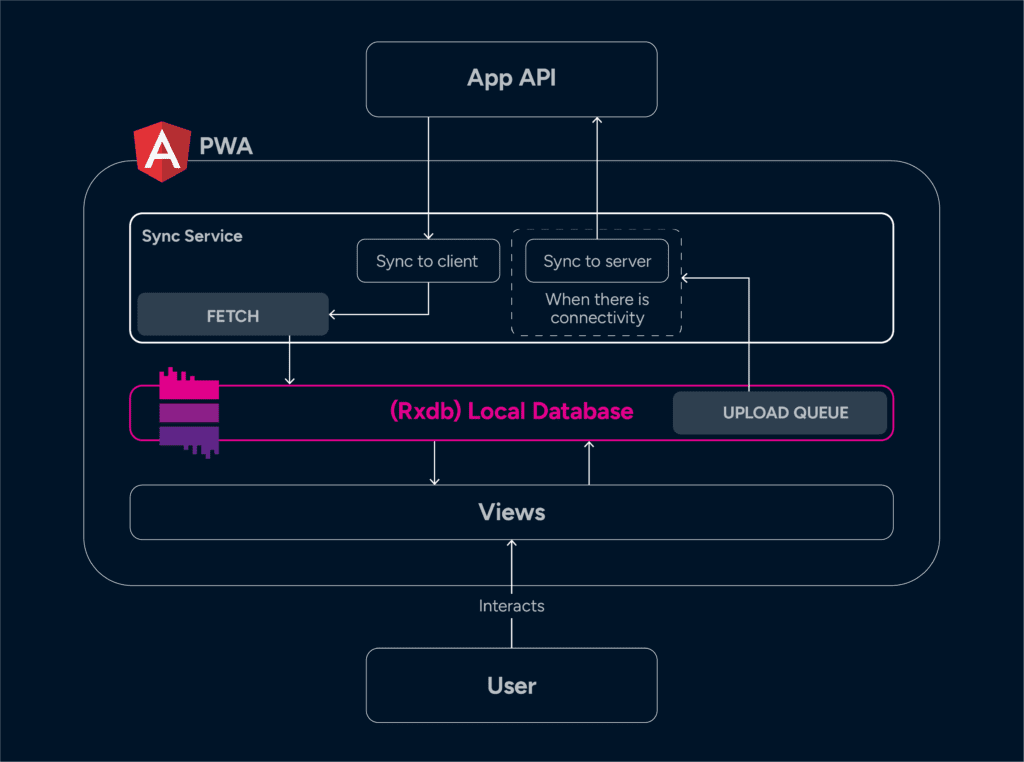
Client to server
If the device is online, the database will immediately be replicated to the backend. When a device is offline, the replication will pause and continue when the client goes online again. We can create a very simple Angular service to handle this. The service responsible for syncing the client to the server simply needs to listen for connection state changes in order to resume or pause syncing.
declare const window: any;
@Injectable({ providedIn: 'root' })
export class OnlineOfflineService {
private internalConnectionChanged = new Subject<boolean>();
get connectionChanged() {
return this.internalConnectionChanged.asObservable();
}
get isOnline() {
return !!window.navigator.onLine;
}
constructor() {
window.addEventListener('online', () => this.updateOnlineStatus());
window.addEventListener('offline', () => this.updateOnlineStatus());
}
private updateOnlineStatus() {
this.internalConnectionChanged.next(window.navigator.onLine);
}
}
We used RxDB’s replication push handler to implement the replication over a REST API we implemented and exposed on our backend (AWS API Gateway). RxDB provides you with a replicateRxCollection function. You specify which collection you want to replicate, with some configurations, and whenever there are changes to that RxDB collection, the replication push handler will execute. RxDB uses a checkpoint to identify what has changed and what needs to be replicated. This checkpoint is a specific field. By default, and in our case, this field is “updatedAt”, which is the timestamp when that record was last updated.
this.replicationState[`${collection}${path}`] = replicateRxCollection({
collection: this._database[collection], // the collection
replicationIdentifier: `sync-${collection}${path}-to-prod-v1-sync-push`,
live: true, // to trigger the push handler immediately as changes are made
retryTime: 600 * 1000,
waitForLeadership: true, // for multi browser functionality
autoStart: false, // only start when specified
deletedField: '_deleted', // mark deleted items as _deleted = true,
push: { // implement custom push replication functionality
async handler(docs) {
let response;
switch (collection) {
case Collection.USER_TABLE:
// Push data to the backend using a HTTP REST API
response = await fetch('https://apigateway.com/api/users, {
method: 'POST',
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json'
},
body: JSON.stringify({ docs })
});
break;
case Collection.INTERACTION_LOG_TABLE:
// ...
}
return response;
},
modifier: (d) => d,
},
});
this.replicationState[`${collection}${path}`].start()
Server to client
The decision and rules about when and how to do this would entirely depend on your application’s use case. In our use case, an initial sync of ALL the data that’s required for the application to run offline is what made sense. RxDB also allows you to implement a pull handler similar to the push handler. Using the built-in pull handler can introduce conflicts between server data and client data that you need to manage.
Our solution was to sync the server data to the client on login and enable the user to manually sync from the server to the client when they want by pressing a button. This would overwrite the data in the local storage, removing the need for conflict management. In order to not overwrite local data that hasn’t been synced yet, the manual server-to-client sync is only enabled if there’s no local data that hasn’t been synced to the server yet. A little bit of UX is required to enable this functionality to be accessible and understood by the user.
Other key takeaways
Let’s look at some highlights of using offline first.
Improved UX
Users are impatient and don’t like waiting, and with reading from and writing to the local database, we see next to zero loading times. In fact, it’s very rare to see a loading spinner when fetching or writing data directly to and from the local database. This is a thing of dreams, and is almost impossible to achieve with the traditional approach of loading data from the API as and when the view that requires it is loaded.
Loose coupling with RxDB
Using a custom API to push database changes to the backend means the tables and schemas on the front end and back end don’t have to be direct replicas of each other. Fetching data also happens over the API where business logic can take place on the backend and something closer to a view-specific model can be returned and stored on the front end. Avoiding having the business logic on the front end is ingrained into our being as software developers from a very early ‘age’.
This solution allows for less coupling between the local and backend databases. You could switch out the backend database to anything else as long as you don’t change the API contract. The approach we went for is to have view tables that are used to render the UI and update tables with specific updates that need to be pushed to the backend.
Competitive edge
In most cases, an offline-first solution would differentiate your system from the competition. It’s not simply a feature you can add on after the fact. Enabling certain offline functionality can be seen as a feature, but that wouldn’t be labelled as offline-first. As this article demonstrates, it requires careful consideration and decisions from the beginning.
Conclusion
This was an eye-opening experience for me. This my first time building an LMS and my first time designing a system to be offline-first. The value added to the problem it would be solving was clear from the beginning; however, the added benefits only became clear when testing of the features began. I would expect to see more offline-first solutions implemented as we continue to deal with a more digital world while balancing the realities of life in South Africa.
Furthermore, this problem is largely solved, and there are many off-the-shelf solutions available that can cater to your various needs and specific architectures. PowerSync is one to look out for and should definitely be revisited when support for more technologies is rolled out.
Lastly, as I have reiterated throughout this article, it’s no small task and should not be considered as something to be added on after that fact – that would be setting yourself up for a massive, easily avoidable refactor.