Introduction
AWS Step Functions is a powerful service that allows you to build, run, and visualise workflows composed of AWS Lambda functions and other AWS services. One use case for Step Functions is to create a workflow for deleting a user in your application. This post will walk you through how to use AWS Cloud Development Kit (CDK) to create a Step Functions workflow that deletes a user in a safe and controlled manner.
Defining the task
The first step in creating a Step Functions workflow is to define the different tasks that will be executed. In this case, we will have several tasks that are executed in parallel branches.
Suppose we have three DynamoDB tables storing different elements of the user’s data:
- History table – stores user’s past events
- Future table – stores user’s future events
- Users table – stores any other data about the user
We can run the processes for the first two tables in parallel However, the last table can only be processed if both of the previous tables were successfully processed. Since we are using DynamoDB tables, we don’t have to worry about developing a SQL solution.
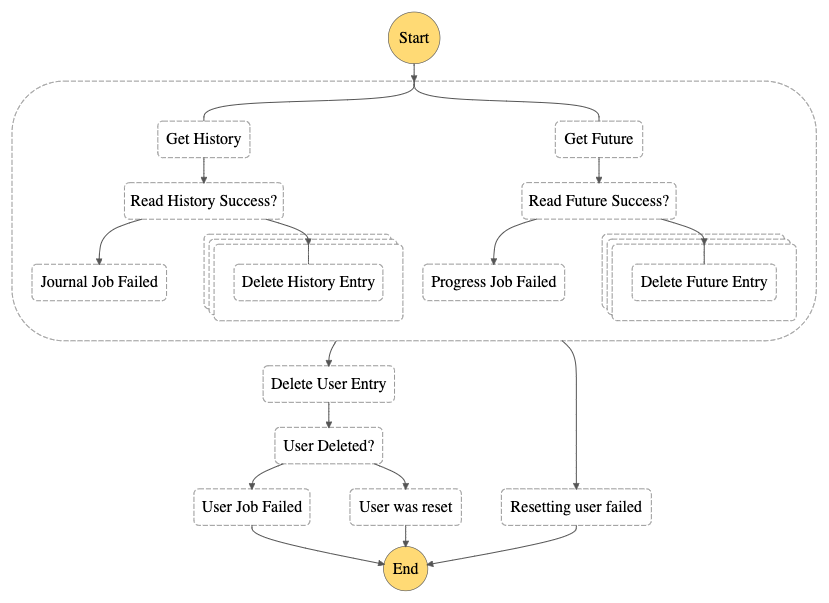
The following image is the result of what we will create in this tutorial.
Implementation
Assuming you have already installed and configured the AWS CDK, here is an example of how you can use the CDK to create the Step Functions workflow for deleting a user. If you have not installed the CDK yet, you can follow the official documentation.
Note: The definition of the actual lambda functions is beyond the scope of this post. It is assumed that you already have lambda functions at the ready. If not, feel free to follow the official documentation to create a few.
Step 1: Import necessary modules in the stack
import { Construct } from 'constructs';
import { App, RemovalPolicy, Stack, StackProps } from "aws-cdk-lib";
import * as dynamodb from "aws-cdk-lib/aws-dynamodb";
import { BillingMode } from "aws-cdk-lib/aws-dynamodb";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { JsonPath, Map, Parallel, Pass, StateMachine, StateMachineType, TaskInput, Succeed, Choice, Condition, Fail, LogLevel } from "aws-cdk-lib/aws-stepfunctions";
import { LambdaInvoke } from "aws-cdk-lib/aws-stepfunctions-tasks";
import { join } from "path";
import { _FUTURE_ENTRIES_TABLE, _HISTORY_ENTRIES_TABLE, _USER_TABLE } from '../shared/variables';
import { LogGroup, RetentionDays } from 'aws-cdk-lib/aws-logs';
*Addendum 1
Step 2: Define parallel state
We plan on running multiple processes concurrently. In order to do this, we need to make use of the Parallel state.
The Parallel state is a state that allows you to parallelise the execution of multiple branches of your state machine. You use it by defining an array of branches, each containing a series of states. The entire state needs to be completed before the state machine transitions to the next state, and if one of the branches throws an error, the entire state machine is stopped.
Let’s just define the Parallel state for now, we will get back to it later on.
const parallel = new Parallel(scope, "WorkInParallel", {
resultPath: JsonPath.DISCARD
});
*Addendum 2
Foursome more insight:
resultPath: JsonPath.DISCARD Deletes any JSON at the end of the parallel function. This means that the next task will be presented with the original input data from the start of the state machine.
Step 3: Define error tasks
We need to create some error states in case any of the lambdas fail.
const historyFailed = new Fail(scope, 'History Job Failed', {
cause: 'AWS Job Failed',
error: 'Failed to process',
});
const futureFailed = new Fail(scope, 'Future Job Failed', {
cause: 'AWS Job Failed',
error: 'Failed to process',
});
const userFailed = new Fail(scope, 'User Job Failed', {
cause: 'AWS Job Failed',
error: 'Failed to process',
});
*Addendum 3
Step 4: Define lambda functions for different tasks
Next, we define the lambda functions. These can be any lambda functions at your disposal. However, for the purpose of this tutorial, let’s cover the basic functions we would like to achieve:
- We won’t need to update or create any entries.
- We need to retrieve entries only from the History and Future tables.
- We need to delete entries from the History, Future, and User tables.
Therefore we can make these assumptions:
- We don’t need to define any update or create lambda functions.
- We only need to define read lambda functions for the History and Future tables.
- We need to define delete lambda functions for all three tables.
Let’s start with the History functions.
const readFromHistoryFunction = new NodejsFunction (this, 'readFromHistory', {
entry: join(
__dirname,
"..",
"services",
"read.ts" // File name of lambda
),
handler: 'handler',
functionName: 'ReadFromHistory',
environment: {
TABLE_NAME: _HISTORY_ENTRIES_TABLE(),
PARTITION_KEY: "userId",
}
});
const deleteFromHistoryFunction = new NodejsFunction (this, 'deleteFromHistory', {
entry: join(
__dirname,
"..",
"services",
"delete.ts" // File name of lambda
),
handler: 'handler',
functionName: 'DeleteFromHistory',
environment: {
TABLE_NAME: _HISTORY_ENTRIES_TABLE(),
PARTITION_KEY: "userId",
}
});
*Addendum 4
Now for the Future functions.
const readFromFutureFunction = new NodejsFunction (this, 'readFromFuture', {
entry: join(
__dirname,
"..",
"services",
"read.ts" // File name of lambda
),
handler: 'handler',
functionName: 'ReadFromFutureFunction',
environment: {
TABLE_NAME: _FUTURE_ENTRIES_TABLE(),
PARTITION_KEY: "userId",
}
});
const deleteFromFutureFunction = new NodejsFunction (this, 'deleteFromFuture', {
entry: join(
__dirname,
"..",
"services",
"delete.ts" // File name of lambda
),
handler: 'handler',
functionName: 'DeleteFromFutureFunction',
environment: {
TABLE_NAME: _FUTURE_ENTRIES_TABLE(),
PARTITION_KEY: "userId",
}
});
*Addendum 5
And finally, the User function.
const deleteFromUserFunction = new NodejsFunction (this, 'deleteFromUser', {
entry: join(
__dirname,
"..",
"services",
"delete.ts" // File name of lambda
),
handler: 'handler',
functionName: 'DeleteFromUserFunction',
environment: {
TABLE_NAME: _USER_TABLE(),
PARTITION_KEY: "userId",
}
});
*Addendum 6
To reiterate, we’ve defined five different lambda functions:
- The read lambdas:
- These retrieve all the data from their respective tables for a specific user
- Each lambda returns a json file containing a list of entries
- This json file is used as input for a Map state that we will cover in the next section.
- The delete lambdas (History and Future):
- These delete each entry in the list of entries retrieved from the read lambdas from the respective tables.
- These only return a success or failed message.
- The delete lambda (User):
- This will delete the user from the Users table.
- Uses the initial input for the state machine as input.
- It will only return a success or failed message.
Step 5: Define task workflow
Next, we need to loop through multiple data sets to delete the specified entries. To do this, we will use a Map.
A Map is a state to run through a set of workflow steps for each item in the dataset. These steps are executed in parallel, which significantly reduces processing time. A variety of input types can be used in a Map state, including a JSON array, a list of AWS S3 objects, or a CSV file.
Two types of processing modes are provided for using the Map state: Inline mode and Distributed mode.
- Inline: Limited-concurrency mode.
- Runs in the context of the workflow that contains the Map state
- Execution history is added to the parent’s history
- Only accepts JSON arrays
- Only supports up to 40 concurrent iterations
- Default mode
- Distributed: High-concurrency mode.
- Runs each iteration as a child workflow execution
- Each child has its own separate execution history
- Up to 10,000 parallel child workflow executions
- Accepts all types of input
Inline should be used if the execution history won’t exceed 25 000 entries or if more than 40 concurrent iterations are required.
Distributed should be used if any of the following is true:
- The size of your dataset exceeds 256 KB
- The workflow’s execution event history exceeds 25,000 entries
- You need a concurrency of more than 40 parallel iterations
Therefore, we will use the default Inline mode for this tutorial, as we do not expect to exceed any of these restrictions.
Map states have an iterator field specifying the input that defines a set of steps that process each element of the array. This field is required if you wish to repeat a specific step multiple times, such as calling the delete Lambda.
We need to define a Map state for each table that needs to be iterated. Let’s start with the history table:
const deleteHistoryMap = new Map(this, 'Deleting History Entries', {
itemsPath:'$.entries',
});
*Addendum 7
itemsPath indicates the array that needs to be looped.
Next define the lambda that will delete each history entry.
const deleteHistory = new LambdaInvoke(this, 'Delete History Entry', {
lambdaFunction: deleteFromHistoryFunction,
payload: TaskInput.fromObject({
'queryStringParameters': {
'userId': JsonPath.stringAt('$.userId'),
'sk': JsonPath.stringAt('$.sk')
}
})
});
*Addendum 8
const readHistory = new LambdaInvoke(this, 'Get History', {
lambdaFunction: readFromHistoryFunction,
inputPath: "$.body",
outputPath: '$.Payload',
}).next(new Choice(scope, "Read History Success?")
.when(Condition.stringEquals('$.status', 'failure'), historyFailed)
.when(Condition.stringEquals('$.status','success'), deleteHistoryMap));
*Addendum 9
inputPath defines where the input data is located in the JSON. outputPath indicates where the input data for the next task will be located.
The .next field is a transition field used to execute the next stage in the step function. Most states only allow for one transition field, however, some flow-control states, such as Choice, allow you to specify multiple transition rules. States can have multiple incoming transitions from other states.
As specified before, the Choice state is used to control the flow of the state machine. It does this by adding conditional logic to a state machine, similar to an if statement. It uses Choice rules which use comparison operators to compare input to a specified value, such as checking if a number is larger than 10.
In our case, the process will be terminated when the read lambda returns a “failure” message. If it returns a “success”, it will continue with the delete state.
Lastly, as mentioned before, an iterator field is required for the Map as we want to call the delete lambda multiple times.
deleteFutureMap.iterator(deleteFuture);
*Addendum 10
Repeat this for the future lambdas as well.
Finally, define the delete user lambda.
const deleteUser = new LambdaInvoke(this, 'Delete User Entry', {
lambdaFunction: deleteFromUserFunction,
inputPath: "$.body"
});
*Addendum 11
Step 6: Define Step Function workflow
We can now complete the Parallel state that we defined earlier. In order to do this, we need to define a sequence using the above definitions as steps. Retrieving and deleting entries from the History and Future tables will happen concurrently. Therefore, we can add them as branches to the Parallel state.
parallel.branch(readHistory);
parallel.branch(readFuture);
*Addendum 12
Before we define the next state to be executed, we need to be able to catch any error that might take place, as well as define a success state so the state machine knows when to stop.
In order to catch errors, we can use the addCatch field. This field looks for a matching “catcher” within the addCatch field. If it is found, the state machine will transition to whichever state has been defined in the next field of the addCatch.
Let’s add an addCatch to the Parallel state.
const sendFailureNotification = new Pass(this, 'Resetting user failed');
parallel.addCatch(sendFailureNotification);
*Addendum 13
Next, let’s use a Succeed state to indicate to the state machine that it was successfully executed and can stop processing.
const closeOrder = new Succeed(this, 'User was reset');
*Addendum 14
Now we can weave it all together into one sequence.
- First, we define the next state after the Parallel state executes its branches successfully, which is “deleteUser”.
- After that state is complete, we transition to a final Choice state which checks whether the user was successfully removed from the table.
- If they were, the Succeed state is called.
- If they were not, the Fail state for the user is called.
parallel.next(deleteUser)
.next(new Choice(scope, "User Deleted?")
.when(Condition.numberEquals('$.Payload.statusCode', 200), closeOrder)
.otherwise(userFailed));
*Addendum 15
Finally, we can define the state machine itself using the Parallel state we defined above. This will execute the state machine whenever it is invoked via an API or any other means.
let stateMachine = new StateMachine(this, "resetuser", {
definition: parallel,
logs: {
destination: new LogGroup(this, "StepLogGroup", {
retention: RetentionDays.ONE_DAY,
}),
includeExecutionData: true,
level: LogLevel.ALL
},
stateMachineType: StateMachineType.EXPRESS,
});
*Addendum 16
Step 6: Deploy
We can deploy the stack by running the following in the console:
cdk deploy
Conclusion
In this example, we have defined five Lambda functions, one for each task in the workflow.
- The readFromHistoryFunction is responsible for getting the user’s data from the history table
- The deleteFromHistorysFunction is responsible for removing the user’s data from the history table
- The readFromFutureFunction is responsible for getting the user’s data from the future table
- The deleteFromFutureFunction is responsible for removing the user’s data from the future table
- The deleteFromUsersFunction is responsible for removing the user’s data from the user’s table
We also defined error states and success and fail tasks.
Finally, we have defined the Step Functions defining the parallel workflow and assigning it to a newly created StateMachine.
After the stack is deployed, you can use the AWS Step Functions console to start execution of the deleteUserWorkflow state machine and monitor its progress. The result of execution should look similar to the following if successful.
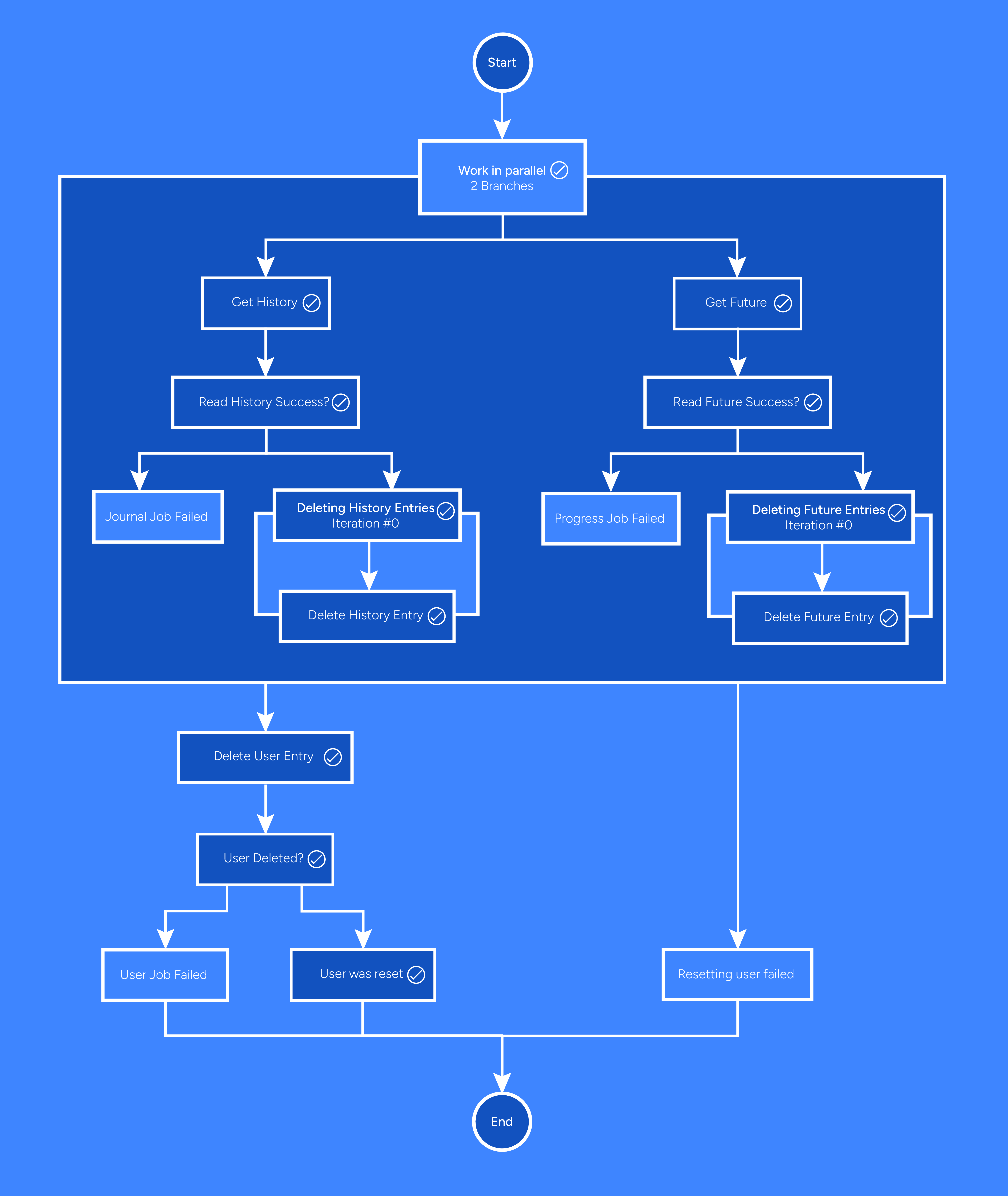
In addition, you can use the CloudWatch logs and metrics to monitor the execution of your Lambda functions and troubleshoot any issues that may arise during the user deletion process.
In conclusion, Step Functions make it easy to use multiple lambda functions, and other AWS services, synchronously and/or asynchronously to perform complex data processing tasks. It removes the need for multiple API calls from the client’s side and eliminates the need to process it all in a single Lambda function.
All the code can be viewed here.
Addendum
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L1-L10&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L20-L22&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L24-L37&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L93-L121&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L144-L172&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L194-L207&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L214-L216&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L218-L226&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L228-L234&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L262&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L266-L269&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L271-L272&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L275-L276&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L279&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L281-L284&style=default&type=code&showFullPath=on&showCopy=on“></script>
- <script src=”https://emgithub.com/embed-v2.js?target=https%3A%2F%2Fgithub.com%2Fscfourie47%2Faws_step_functions_tutorial%2Fblob%2F4494059673aa65338402ac5d47f36af86008d637%2Flib%2Faws_step_functions_tutorial-stack.ts%23L286-L296&style=default&type=code&showFullPath=on&showCopy=on“></script>